QSPR 基礎理論
QSPR模擬技術之主要目的是為了量化材料性質與分子結構特徵間之關係,通常可以簡單的數學公式來表示(式(1)),即分子或材料之性質為分子描述因子( MolecularDescriptor )之函數1:Property = F(Molecular Descriptors)
其中描述因子為分子結構經過演算後之數值,如分子之 HOMO、LUMO 能階、Dipole,或是在 XY 面之投影面積等。因此,此模型之描述公式不但可顯示出該性質與哪些參數(描述因子)有關,若在一個可靠的 QSPR 模型下,亦可協助我們預測不在公式內的新化合物性質數值,相關之QSPR基礎理論與實例可參考Katritzky等人發表的論文。
QSPR 模擬流程
1. 數據資料分類與選擇( Data Set Selection )
取得化學結構與實驗數據後, 第一步動作就是先將不同結構之分子做分類( Grouping ),以化學結構相近者歸為一類,如液晶分子中常會以不同連接基或液晶核做分類。建立不同結構分子資料庫可使預測結構更為準確,一般來說,相近結構分子之資料庫至少需 25筆以上才具有一定之可信度。所有的 Data Set 可再被分為訓練數據集( Training Set )與測試數據集( Test Set )兩種數據,其中 Training Set 為用於建構 QSPR 預測模型之數據,而 Test Set 則是用來驗證或測試此 QSPR 模型是否可靠或穩健,Test Set 亦可變成 Training Set,經重新取樣而建構出另一個 QSPR 模型,經過反覆調整以找出最佳之 QSPR 模型。
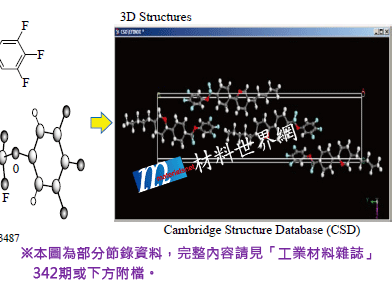
圖二、液晶分子之X-ray晶格結構圖
3. 描述因子選擇與計算( Descriptor Calculation )
除了上述軟體內建之描述因子外,亦可從學理或經驗上得知某預測性質與某種特殊結構有高相關性,可手動自己建立 Marked Structure 之描述因子(圖三),包含鎖定環的數目( # of Ring )、特定元素數目( Element Count(F ))、環的種類( Ring )、環與環間之連接基( Interconnection )等 Marked Structure 方式,以正確反應出此類描述因子與預測性質間之重要性。
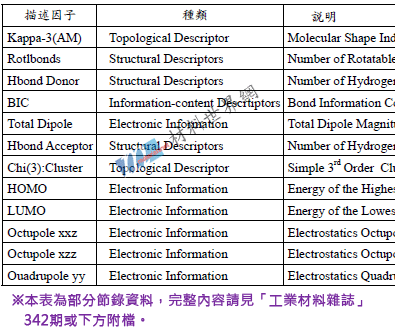
表二、描述因子之列舉
4. 演算與預測公式(Developing the Model)
GFA演算法為模擬自然界生物演化過程及運作機制之近似方法,透過遺傳之方式(即選擇與淘汰同步進行之過程),最後產生最適合生存物種之理論,如圖四所示,一開始經由基因交換,彼此相互競爭選擇,經過多代之演變,最後將趨於平衡,即可獲得最佳之預測公式。在MS 5.0模擬軟體中,GFA數據統計分析之可設定參數包含Population、Max Generations、Initial Equation Length、Max Equation Length等,透過改變不同參數設定以找出最佳之預測公式。
多維性質QSPR模擬
對於高性能、高應用性材料而言,常需具有多項最佳之物理、化學等性質,因此,建立可同時預測兩種以上材料特性之模擬技術亦已開始被國際上研究單位或公司所關注。例如 Rohm and Haas 公司利用分子拓樸( Molecular Topology )與基因演算( Genetic Algorithm )建立最佳化之 QSPR 模型與二維性質模擬圖,成功地運用於生物可分解型高分子( Biodegradable Polymers )研究上。該團隊先使用了一組 Brocchini 等人建立之聚合物資料庫( Polymer Library ),搭配使用 Accelrys® Cerius 2 軟件組衍生出虛擬資料庫( Virtual Library )……以上為部分節錄資料,完整內容請見下方附檔。
作者:金志龍、王藝蓉 / 工研院材化所
★本文節錄自「工業材料雜誌」342期,更多資料請見下方附檔。